Playing nicely with GenAI§
2024 Apr 14
Early ideas about how to author docs that work well with generative AI.
For the past month I’ve been prototyping docs experiences along the lines of Supabase Clippy. This post outlines my early ideas about how to author docs to make them easy for generative AI to consume. Hat tip to my colleagues Kyo Lee and Rundong Du for figuring a lot of this stuff out.
(I am focused on using generative AI to help the users of docs get their tasks done faster. Using generative AI to improve authoring, for example, is a totally different topic. Hat tip to my colleague Dave Holmes for highlighting the need to disambiguate these “generative AI for docs” discussions into more focused sub-topics.)
Disclaimers§
These are early ideas. I am not an AI expert. I have only been experimenting with context injection approaches. I have not done any experimentation with fine-tuning. I have only prototyped; I have not shipped anything to production. In general this space is evolving very quickly; everything you see in this post might be irrelevant in a year.
Summary§
Docs search infrastructure is still important and may become more important. In order to get useful answers from generative AI, you need to preprocess the query by finding docs related to that query, and then “inject that context” into the prompt before sending it to generative AI. This is how you keep the AI’s answer grounded in facts.
You’ll probably want to keep the context injection as minimal as possible. The most production-ready generative AI at the moment can only handle 16K characters of input. You are billed based on the size of your input.
Small docs will probably play more nicely with generative AI than large docs. At minimum, your docs system should be able to take a large doc and chunk it up into small sections of logically related content. I expect that a lot of docs systems will drag their feet on the “chunk large docs into small sections of logical content” feature therefore I imagine the path of least resistance for technical writers working within the constraints of those systems to be to just write small docs.
If the architecture pioneered by ChatGPT Plugins takes off then web service API references should conform to the OpenAPI specification and should be targeted towards end users and generative AI rather than developers. See plugins.
Context injection versus fine-tuning§
What we informally call “AI” is mostly synonymous with what OpenAI and others call a “model” in their official docs. The model is the thing that receives your questions and replies with answers.
With context injection you are working with an “off-the-shelf” model. This model has been trained with general data. It probably doesn’t know much about your specific domain. To get useful answers out of it you need to provide it lots of context about your domain.
(Update (29 Apr 2023): It seems like the more common term for this architecture is retrieval-augmented generation (RAG). In future posts you’ll see me using that term instead of context injection.)
With fine-tuning you are working with a customized model that has been enhanced or “trained” with your domain-specific information. You can ask it questions about your domain (without injecting domain-specific context into every single query) and get accurate answers because the domain-specific information has been baked into the model.
My only thought about fine-tuning§
I haven’t done any experimentation with fine-tuning so I don’t have much to say (other than the next paragraph).
I took a crash course on machine learning last week. The instructors spent a lot of time discussing how to train models. To train a model successfully you need to understand your raw data deeply and prepare it very carefully. Since fine-tuning is essentially model training, I expect it will take us a while to collectively figure out how to apply fine-tuning for docs needs. It is complicated stuff.
A crash course on context injection§
I think context injection is going to be the more common strategy for building docs-related generative AI features for a while. So, to understand how to author docs that play nicely with generative AI, you’ve got to get a handle on context injection.
Let’s ground this discussion in a concrete example: Supabase Docs. The implementation is explained in-depth at How I Built Supabase’s OpenAI Doc Search.
Overview§
You click Search docs and you see an option to Ask Supabase AI:
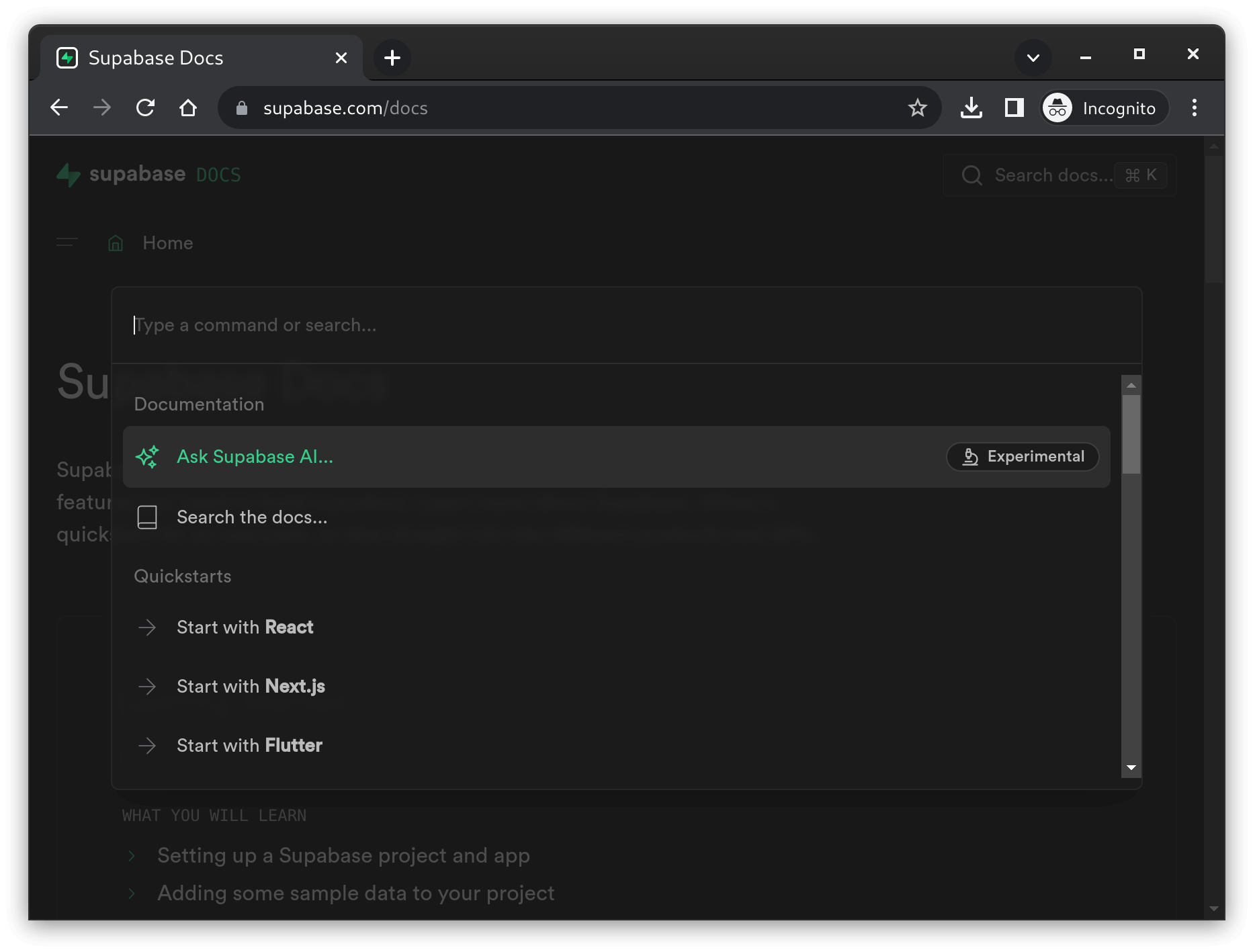
You ask a question:
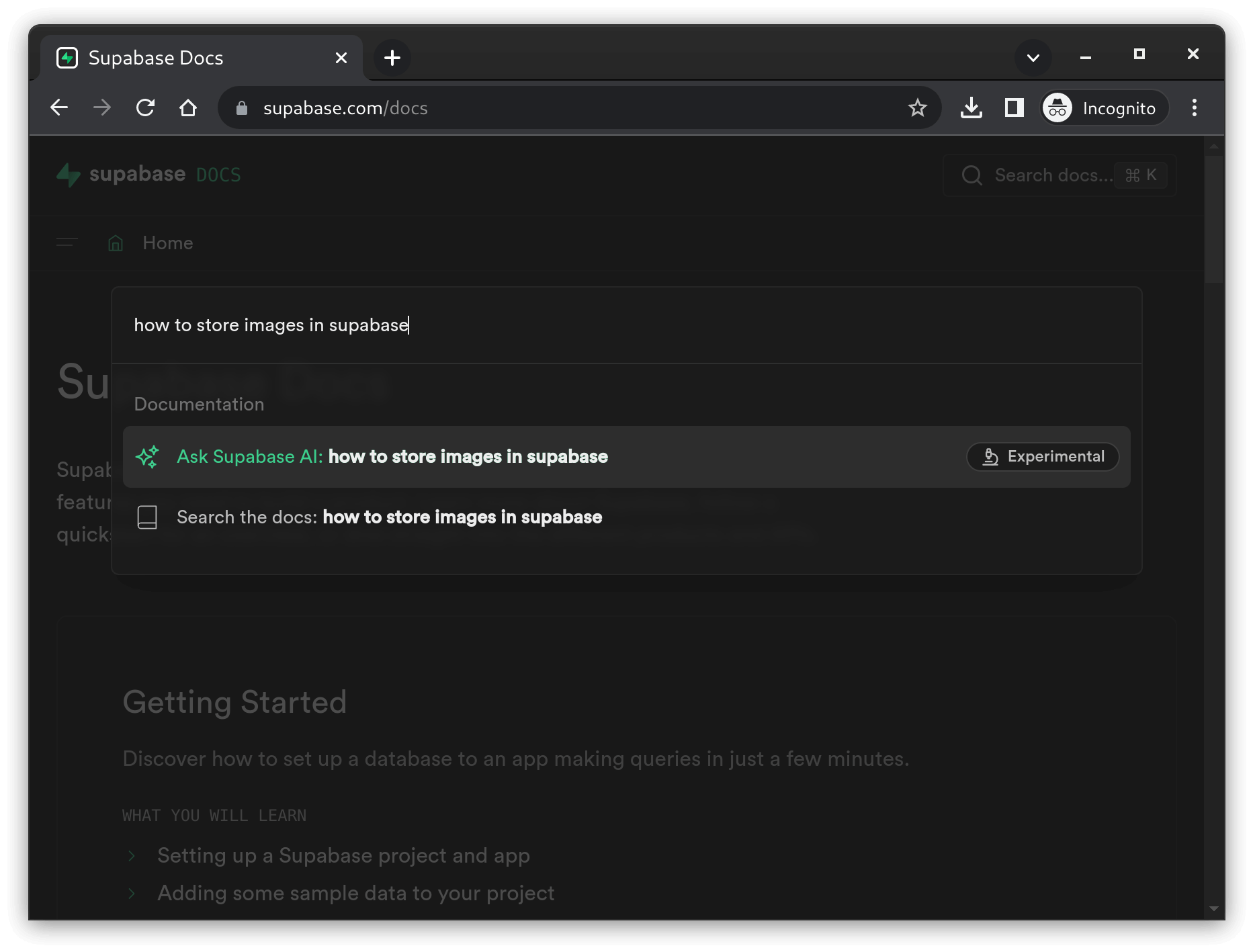
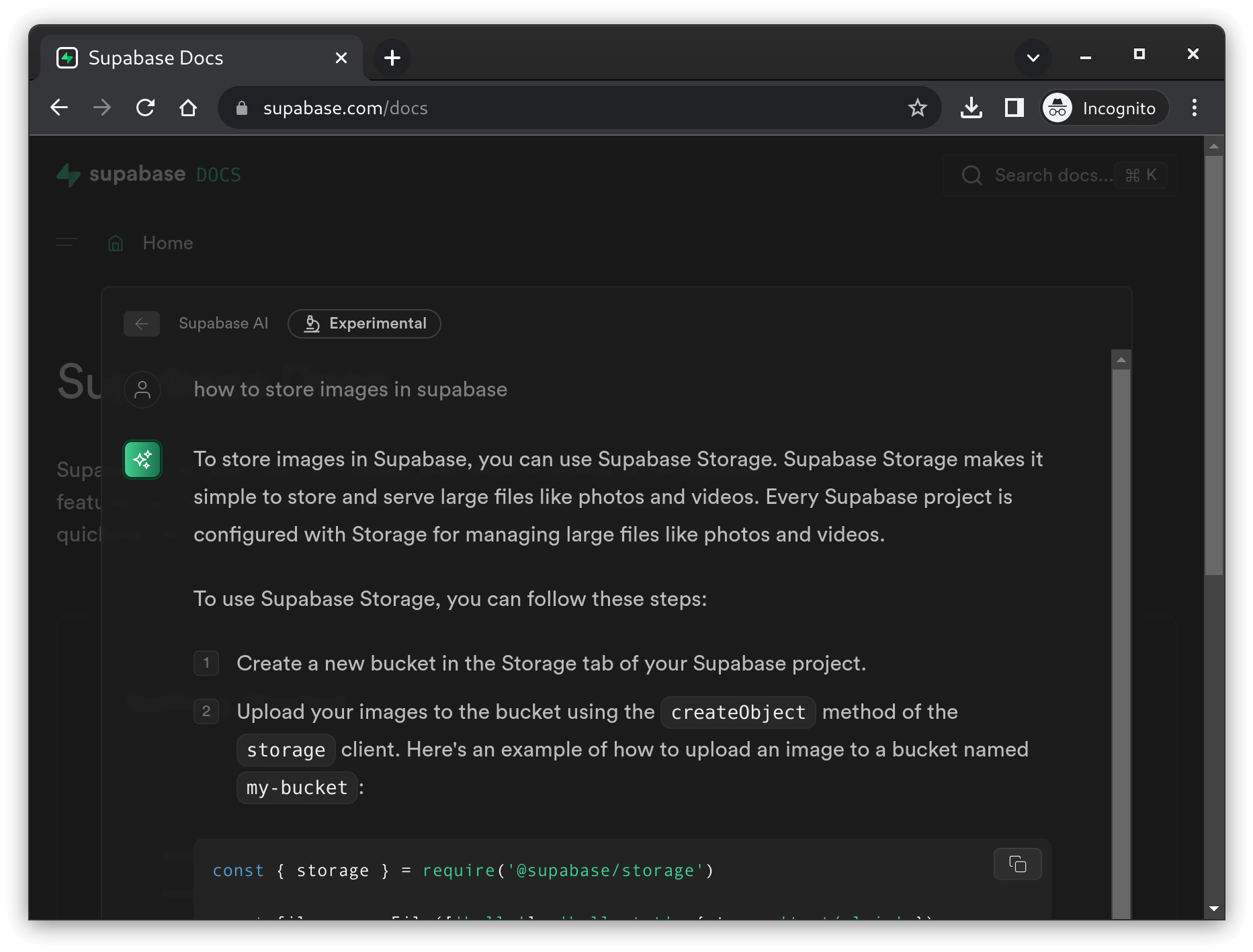
Supabase sends the question to the OpenAI Completions API and then displays the answer from OpenAI:
How it works§
The question that you asked was:
how to store images in supabase
But the question that was actually sent to OpenAI follows this pattern:
You are a very enthusiastic Supabase representative who loves to help
people! Given the following sections from the Supabase documentation,
answer the question using only that information, outputted in markdown
format. If you are unsure and the answer is not explicitly written in
the documentation, say "Sorry, I don't know how to help with that."
Context sections:
${contextText}
Question:
${sanitizedQuery}
Answer as markdown (including related code snippets if available):
(We know exactly what prompt Supabase sends to OpenAI because the code is open source. You can view it at …/clippy-search/index.ts.)
The first paragraph provides instructions to the model about how it should respond.
The next paragraph contains chunks of relevant content from the docs.
${contextText}is a placeholder that will be replaced with actual docs content before Supabase calls the OpenAI API. This is where generative AI might have a big impact on how we author docs.${sanitizedQuery}is your original query (how to store images in supabase) that has been fed through OpenAI’s [Moderation] API to ensure that the model can consume the query safely.The purpose of the last paragraph is the same as the purpose for the first.
“Chunks of relevant content from the docs”§
${contextText} is “chunks of relevant content from the docs”. This is how
you keep the model’s answer grounded in facts. How do you determine chunks of
relevant content? I am pretty sure that you can use any approach. For example,
maybe your docs site is already integrated with Algolia. You should be able
to feed the query (how to store images in supabase) into Algolia and then
use the content from the top Algolia results as your ${contextText}.
However, a lot of people (including Supabase Docs) are using embeddings to
find relevant content. It is basically AI-powered search. More on embeddings in
the next section.
Here is a key constraint. You might be thinking, “let’s just prepend every question with our entire corpus of documentation.” The first problem is that these models currently can only handle around 16K characters (not words). The second problem is that you are billed based on the size of your inputs. Maxing out your input size on every API call will probably get expensive.
(Here is how to calculate the 16K character limit. Models describes the
token limit for each model. gpt-3.5-turbo, the most production-ready model
at the moment, has a token limit of 4K. What are tokens and how to count
them? says that a token is roughly 4 English characters.)
Embeddings§
I have a hunch that embeddings will have many applications for docs so let’s dig into them a bit.
Embeddings are pretty much statistical representations of text. You don’t actually use embeddings when communicating with the OpenAI API. You only use them to figure out what docs content is related to a query.
In Python you generate an embedding for our favorite query like this:
openai.Embedding.create(
input=['how to store images in supabase'],
model='text-embedding-ada-002'
)
OpenAI returns an array of numbers like this:
[
-0.006929283495992422,
-0.005336422007530928,
...
-4.547132266452536e-05,
-0.024047505110502243
]
Here’s another clincher. In order for this to be useful you also must have
embeddings for all of your docs content. In Sphinx this was actually pretty
trivial to set up. This post is getting long and I am tired so I will save
that discussion for another day. Long story short, when you build your docs
site, you need to chunk each doc into small, logical sections and then generate
an embedding for each section. Once you have that “database” of embeddings for
every docs section, it’s pretty easy (for a proficient programmer) to compare
the query embedding against each docs section embedding in order to find out
what docs sections are most closely related to the query. You then map the
docs section embeddings back to the actual docs content and replace
${contextText} with that docs content.
Check out Text Embeddings Visually Explained to build up your intuition about embeddings. It’s a pretty cool rabbithole. Also, it’s such a nice piece of conceptual technical writing!